Ансамблевые машинные предикторы: новый подход к оценке риска госпитальной летальности у пациентов с острым коронарным синдромом
Аннотация
Цель. Оценить эффективность современных ансамблевых моделей машинного обучения (МО) в прогнозировании госпитальной летальности у пациентов с острым коронарным синдромом (ОКС) в сравнении с традиционной клинической шкалой GRACE.
Материал и методы. В ретроспективное исследование включены анонимизированные данные 14420 пациентов с ОКС, госпитализированных в кардиологический стационар. Для каждого клинического случая анализировалось 28 предикторов. На основе этих данных обучены алгоритмы МО: логистическая регрессия, деревья решений, случайный лес (Random Forest), градиентный бустинг (XGBoost, CatBoost). Для оценки качества моделей использовались площадь под ROC-кривой (AUC-ROC), полнота (Recall) и F1-мера. Результаты лучшей модели сопоставлялись с оценкой риска по шкале GRACE. Для интерпретации логики алгоритма применялся SHAP-анализ.
Результаты. Госпитальная летальность составила 6,03% (804 пациента). Алгоритмы на основе градиентного бустинга продемонстрировали наилучшую предсказательную способность. Лидером стала модель CatBoost, показавшая значение AUC-ROC 0,961, статистически значимо превзойдя шкалу GRACE (AUCROC 0,919) на тестовой выборке. SHAP-анализ выявил, что наибольший вклад в прогноз модели вносят: наличие дислипидемии в анамнезе, фракция выброса левого желудочка, класс острой сердечной недостаточности по Killip, возраст и уровень систолического артериального давления. Модель успешно выявила скрытые нелинейные клинические паттерны, включая парадоксальный защитный эффект диагностированной ранее дислипидемии и критическую прогностическую значимость отсутствия анамнестических данных при поступлении.
Заключение. Методы МО, в частности алгоритм CatBoost, обеспечивают более высокую точность прогнозирования госпитальной летальности при ОКС по сравнению с классическими шкалами. Способность алгоритмов учитывать сложные нелинейные взаимосвязи между клиническими показателями делает их перспективной основой для создания точных систем поддержки принятия врачебных решений.
Острый коронарный синдром (ОКС) остается ведущей причиной смертности в развитых и развивающихся странах, несмотря на значительный прогресс в медицине [1]. Своевременная стратификация риска неблагоприятных исходов является краеугольным камнем в выборе тактики ведения пациентов: от нее зависит своевременность перевода больного в отделение интенсивной терапии и выбор стратегии инвазивного вмешательства.
Исторически для этих целей кардиологами используются валидированные балльные системы, наиболее авторитетной из которых является шкала GRACE (Global Registry of Acute Coronary Events, глобальный регистр острых коронарных событий) [2]. Однако традиционные шкалы имеют ряд ограничений. Они базируются на методах линейной регрессии и используют строго ограниченный набор признаков (для GRACE это 8 предикторов). Человеческий организм — сложная система, и связь между клиническими показателями и риском смерти редко бывает строго линейной (например, как чрезмерно высокое, так и критически низкое артериальное давление связано с неблагоприятным прогнозом) [3]. Кроме того, классические шкалы не способны в полной мере использовать огромный массив данных, накапливаемый сегодня в электронных медицинских картах.
В последние годы в кардиологии активно внедряются методы искусственного интеллекта и машинного обучения (МО). В отличие от классической статистики, МО способно анализировать многомерные массивы данных, выявляя скрытые нелинейные паттерны [4][5]. Ряд исследований демонстрирует превосходство МО над традиционными шкалами в предсказании крупных кардиоваскулярных событий [6][7]. Однако внедрение таких моделей требует их обучения и валидации на локальных популяциях, а также преодоления проблемы недостаточной прозрачности алгоритмов для врачей-клиницистов и клинических биоинформатиков.
Цель исследования: разработать и сравнить модели МО для прогнозирования госпитальной смертности пациентов с ОКС на основе крупной выборки, сопоставить их эффективность с традиционной шкалой GRACE, а также интерпретировать логику принятия решений алгоритмом с клинической точки зрения.
Материал и методы
Клинические данные. Исследование носит ретроспективный характер. Использовалась уникальная анонимизированная выборка из 14420 историй болезни пациентов с подтвержденным диагнозом ОКС, проходивших лечение в СПб ГБУЗ «Городская Александровская больница».
Для исключения статистических погрешностей пациенты с неизвестным клиническим исходом (1088 случаев), а также признаки, имеющие >50% пропущенных значений, были исключены. Итоговая выборка составила 13332 пациента. За период госпитализации летальный исход зафиксирован у 804 пациентов (6,03%). В финальный анализ были включены 28 показателей: демографические данные, жизненные показатели при поступлении (артериальное давление, частота сердечных сокращений), данные лабораторных (креатинин, тропонины, глюкоза) и инструментальных исследований (фракция выброса (ФВ) левого желудочка, зоны гипокинеза по эхокардиографии, класс по Killip и др.).
Методы МО. В традиционных шкалах формула расчета риска создается исследователями на основе классической статистики: каждому симптому заранее присваивается фиксированный «вес» (балл). Алгоритмы МО работают принципиально иначе, так компьютерная программа получает массив данных с известными исходами (выжил/летальный исход) и самостоятельно выявляет скрытые математические закономерности [8][9].
В настоящей работе по показателям эффективности были оценены следующие алгоритмы:
- Логистическая регрессия: базовый статистический метод, оценивающий линейный вклад каждого фактора в вероятность события. Метод прозрачен, но плохо справляется с нелинейными связями.
- Дерево решений (Decision Tree): алгоритм, автоматически ищущий параметры, которые лучше всего разделяют пациентов на выживших и умерших, задавая последовательность бинарных вопросов. Напоминает клинический алгоритм сортировки.
- Случайный лес (Random Forest): ансамблевый метод. Алгоритм строит сотни независимых деревьев решений. Каждому дереву показывают только случайную часть пациентов и случайную часть их показателей. Итоговое решение принимается путем «голосования» деревьев.
- Градиентный бустинг (XGBoost, CatBoost): наиболее мощная форма ансамблевого обучения. В отличие от Случайного леса, деревья строятся последовательно. Каждое новое короткое дерево прицельно учится исправлять ошибки классификации сложных пациентов, допущенные предыдущим алгоритмом. В нашем исследовании в качестве основной модели применялась библиотека CatBoost, разработанная для эффективной работы со смешанными табличными данными. Ее преимущество заключается в способности легко усваивать качественные медицинские показатели (наличие заболеваний, пол) и высокой устойчивости к пропускам в клинических данных [10].
- Метод SHAP (SHapley Additive exPlanations, метод аддитивных объяснений Шепли), позволяющий оценить влияние каждого клинического признака на итоговый прогноз, по сути интерпретатор слабого искусственного интеллекта [11].
Проблема дисбаланса классов и валидация. Поскольку абсолютное большинство пациентов (94%) выжили, базовая модель могла бы всем ставить прогноз «выживет» и формально иметь точность 94%, при этом пропуская все смерти. Для решения проблемы дисбаланса классов мы применили метод взвешивания классов (Class Weighting), искусственно увеличив «штраф» алгоритму за ошибку на пациенте с летальным исходом.
Вся выборка была случайным образом, но с сохранением пропорции умерших, разделена на две части: обучающую (80%) и тестовую (20%). Алгоритмы обучались только на обучающей выборке, а оценка качества проводилась на тестовой. Качество оценивали по площади под ROC-кривой (AUC-ROC), метрикам точности (Precision) и полноты (Recall). Для сравнения для каждого пациента из тестовой выборки был высчитан риск смерти по шкале GRACE с использованием оригинальной регрессионной формулы.
Результаты
Сравнение производительности моделей
При тестировании на отложенной выборке современные ансамблевые модели МО продемонстрировали существенное превосходство над базовой логистической регрессией (табл. 1).
Таблица 1
Сравнение предсказательной способности обученных на клинических данных моделей
|
Модель |
AUC-ROC |
F1-мера (баланс) |
Полнота (Recall) |
Точность (Precision) |
|
Логистическая регрессия |
0,936 |
0,44 |
0,850 |
0,30 |
|
Random Forest (Случайный лес) |
0,941 |
0,53 |
0,860 |
0,38 |
|
XGBoost |
0,951 |
0,50 |
0,880 |
0,35 |
|
CatBoost |
0,961 |
0,55 |
0,880 |
0,40 |
Сокращение: AUC-ROC (Area Under the Receiver Operating Characteristic Curve) — площадь под кривой рабочей характеристики приемника.
Лучшей моделью по интегральной способности дифференцировать риски стала модель CatBoost (AUC-ROC=0,961). Модель продемонстрировала высокий показатель полноты (0,880) — это означает, что она способна успешно выявить 88% пациентов, которым угрожает летальный исход, минимизируя критически опасные ложноотрицательные результаты.
Сравнение CatBoost со шкалой GRACE
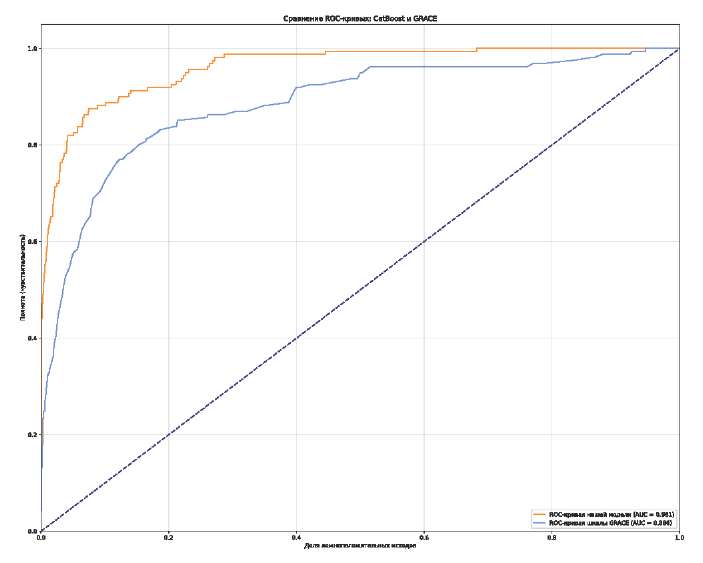
ROC-анализ показал, что предсказательная способность модели МО статистически значимо превосходит традиционную шкалу (рис. 1). AUC-ROC для CatBoost составила 0,961 против 0,919 для шкалы GRACE.

Рис. 1. Сравнение ROC-кривых модели CatBoost и клинической шкалы GRACE на тестовой выборке.
Визуально на всем протяжении графика кривая модели CatBoost располагается выше и левее кривой шкалы GRACE. На индивидуальном уровне анализ показал, что CatBoost точнее ранжирует риски у нестандартных пациентов, где классическая 8-факторная шкала недооценивала угрозу.
Интерпретируемость модели: оценка вклада предикторов (SHAP-анализ)
Для преодоления проблемы «черного ящика» нейросетевых алгоритмов был применен метод SHAP, позволяющий оценить влияние каждого клинического признака на итоговый прогноз [11].
На рисунке 2 представлена сводная диаграмма SHAP. По вертикальной оси предикторы ранжированы по степени их убывающей значимости. Каждая точка — один пациент. Цвет отражает исходное значение показателя (красный — высокие значения, синий — низкие, серый — нет данных). Положение точки по горизонтальной оси показывает влияние признака на прогноз: смещение вправо увеличивает риск летального исхода, влево — снижает риск.

Рис. 2. SHAP-анализ: распределение влияния клинических предикторов на риск внутрибольничной летальности.
Сокращения: АЧТВ — активированное частичное тромбопластиновое время, ДАД — диастолическое артериальное давление, ИМпST — инфаркт миокарда с подъемом сегмента ST, ЛГ — легочная гипертензия, ЛЖ — левый желудочек, МВ-КФК — креатинкиназа-МВ, ОКС — острый коронарный синдром, ОКСбпST — острый коронарный синдром без подъема сегмента ST, САД — систолическое артериальное давление, ЧКВ — чрескожное коронарное вмешательство, ЧСС — частота сердечных сокращений.
Анализ графика продемонстрировал, что алгоритм успешно усвоил фундаментальные законы патофизиологии ОКС, т.е. знания необходимые для прогнозирования госпитальной летальности из набора данных:
- Состояние миокарда и тяжесть острой сердечной недостаточности. ФВ и класс по Killip выступили мощнейшими предикторами. Низкие значения ФВ (синие точки) формируют длинный «хвост» в правой части графика, критически повышая вероятность смерти. Сохранная ФВ (красные точки) смещает прогноз в безопасную зону. Аналогично, высокие классы Killip (III-IV, красные точки) резко сдвигают прогноз в зону летального исхода.
- Системная гемодинамика. Высокие цифры систолического артериального давления (САД) при поступлении (красные точки) ассоциированы с благоприятным прогнозом, в то время как низкое САД (синие точки) выступает машинным маркером кардиогенного шока и истощения резервов.
- Функция почек. Снижение клиренса креатинина (синие точки) и рост уровня креатинина (красные точки) уверенно классифицируются моделью как факторы фатального прогноза.
- Феномен «парадокса дислипидемии». Самым весомым признаком математически выступило наличие дислипидемии, однако вектор ее влияния оказался парадоксальным. Наличие установленной дислипидемии (красные точки) снижает риск внутрибольничной смерти, а ее отсутствие (синие точки) или отсутствие данных о ней (серые точки) — резко повышают риск. С клинической точки зрения этот машинный вывод описывает известное в кардиологии явление [12], пациенты с известной дислипидемией, как правило, находились под наблюдением и принимали статины до развития ОКС, что обеспечивает плейотропный, бляшкостабилизирующий эффект. В то же время «серые точки» (нет данных по анамнезу), уходящие в экстремальную зону риска (далеко вправо), отражают когорту пациентов, поступивших в критическом состоянии (шок, искусственная вентиляция легких, клиническая смерть), у которых сбор анамнеза был физически невозможен. Модель блестяще уловила этот скрытый нюанс.
Обсуждение
Результаты исследования подтверждают актуальный тренд цифровой медицины — МО обеспечивает лучшую прогностическую точность, чем традиционные регрессионные модели [6][8]. Шкала GRACE, обладая неоспоримой клинической ценностью, ограничена 8 фиксированными переменными. Модель CatBoost, используя 28 доступных параметров, формирует более детальный профиль риска пациента.
Важнейшим итогом исследования является как достижение высоких значений метрик (AUC 0,961), так и клиническая прозрачность алгоритма принятия решений, показанная с помощью SHAP-анализа. Алгоритм не просто произвел слепую итерацию, а с высокой точностью сымитировал врачебное мышление: выделил маркеры насосной дисфункции (ФВ левого желудочка, Killip), нарушения перфузии (низкое САД) и органного повреждения (креатинин). Особую ценность представляет способность алгоритма МО выявлять скрытые взаимосвязи, такие как «защитный» эффект подтвержденного анамнеза дислипидемии (маркер предшествующей терапии и комплаентности) и фатальное прогностическое значение отсутствия сведений об анамнезе у тяжелых пациентов [12-15]. У пациентов старческого возраста (углубленный анализ подгрупп) алгоритмы выявили смену приоритетов риска: структурные показатели миокарда уступают место интегральным параметрам системной перфузии.
Внедрение подобных интеллектуальных алгоритмов в виде модулей госпитальных медицинских информационных систем позволит полностью автоматизировать расчет риска, избавляя врача от рутинных вычислений и сигнализируя о скрытом ухудшении состояния больного.
Ограничения исследования. Ограничениями данного исследования являются его ретроспективный дизайн и использование базы данных одного крупного стационара. Для подтверждения универсальности (генерализуемости) модели необходимо проведение проспективных мультицентровых исследований, для облегчения взаимодействия с ансамблевыми моделями врачей клиницистов необходима разработка интерфейса с интегрированной большой языковой моделью-агентом, принимающей команды на естественном языке и интерпретирующей выдачу ансамблей.
Заключение
Разработанная на базе алгоритма градиентного бустинга (CatBoost) ансамблевая модель МО продемонстрировала высокую точность в прогнозировании госпитальной летальности у пациентов с ОКС (AUC-ROC=0,961), статистически превзойдя классическую клиническую шкалу GRACE (AUC-ROC=0,919). Использование SHAP-анализа позволило визуализировать процесс машинного прогнозирования госпитальной летальности, подтвердив его полное соответствие законам клинической патофизиологии. Интеграция таких алгоритмов в медицинские информационные системы способна стать мощным инструментом персонализированной стратификации рисков и поддержки врачебных решений, направленных на снижение госпитальной смертности.
Отношения и деятельность: все авторы заявляют об отсутствии потенциального конфликта интересов, требующего раскрытия в данной статье.
Декларация ИИ. Технологии генеративного ИИ использовались исключительно как вспомогательный инструмент на финальных стадиях работы над текстом рукописи.

Чтобы читать статью войдите с логином и паролем от scardio.ru
Ключевые слова
Для цитирования
Торопов В.Н., Богомолов А.Н., Курочкина О.Н., Ветошкин Р.Е., Соловьёв И.А. Ансамблевые машинные предикторы: новый подход к оценке риска госпитальной летальности у пациентов с острым коронарным синдромом. Российский кардиологический журнал. 2026;31(2S):6885. https://doi.org/10.15829/10.15829/1560-4071-2026-6885. EDN: PFQTXI
Скопировать